
The BoLD (BOdy Language Dataset) Challenge is a competition aimed towards studying and understanding in-the-wild human emotion from body language. We have constructed a large-scale, fully annotated dataset as well as a model evaluation and benchmarking platform to compare model performance towards this objective. Because of a server OS update, the system currently cannot handle emailing of confirmation information. After registering, please email Prof. James Wang (jwang@ist.psu.edu) to let him know so he can manually approve you. We are working to fix the issue, but it will take time because the student who developed this site has graduated.




Problem Description
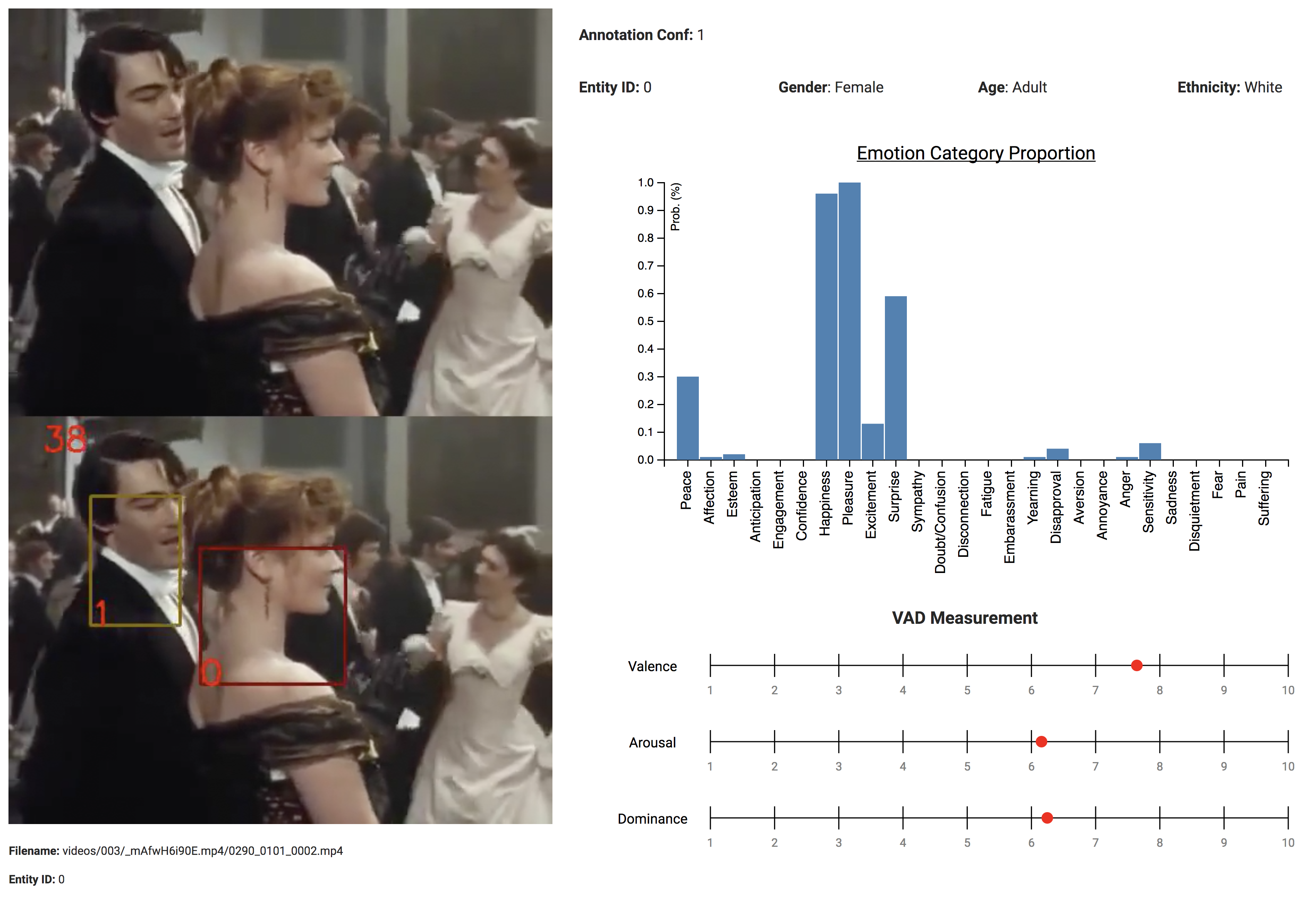
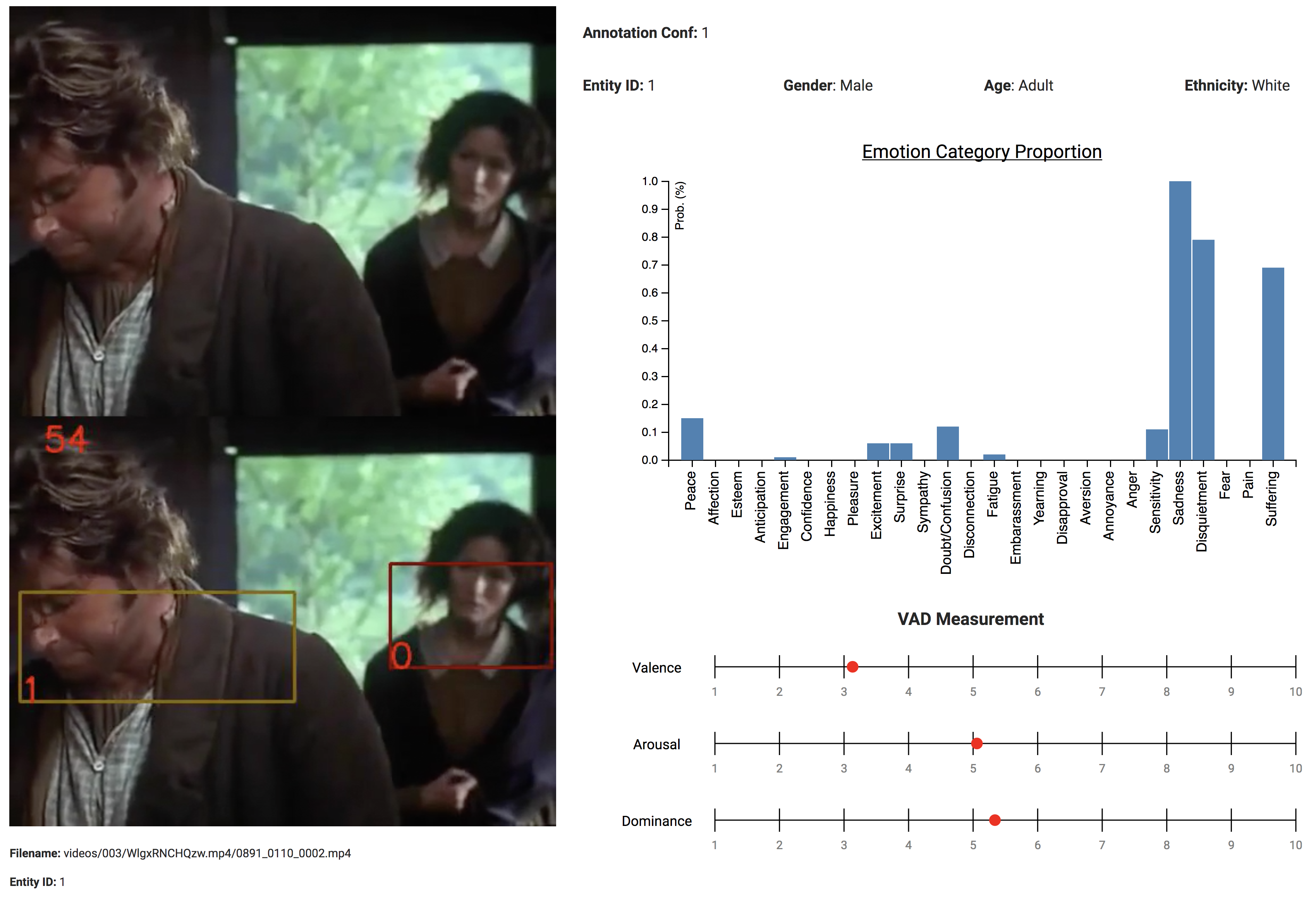
Computerized bodily emotion expression recognition capabilities have the potential to enable a large number of innovative applications including information management and retrieval, public safety, improving patient care, and social media. In this challenge, we invite researchers to develop a model which can have computers understand human emotion from spatiotemporal and human pose data from the BoLD - Body Language Dataset.
Given a selected entity from a short video sequence, the model must evaluate both the 26 discrete emotion cateogries (Peace, Affection, Esteem, Anticipation, Engagement, Confidence, Happiness, Pleasure, Excitement, Surprise, Sympaty, Doubt/confusion, Disconnection, Fatigue, Embarrassment, Yearning, Disapproval, Aversion, Annoyance, Anger, Sensitivity, Sadness, Disquietment, Fear, Pain, Suffering) and the continuous emotion values (Valence, Arousal, and Dominance).
Evaluation Criteria
We evaluate all prediction results on test set submitted to our evaluation server by comparing the results to our holdout ground truth set.
For the evaluation of the categorical outputs, we use the Average Precision
(AP, area under the precision-recall curve) and Area Under the Receiver Operating Characteristic (ROC AUC).
For the evaluation of the continuous outputs, we use the \(R^2\) metric to evaluate the regression values.
The overall model performance is compared with Emotion Recognition Score (ERS), which is defined in the paper.
General Benchmark Rules
For submissions to be qualified to the BEEU, teams must observe and adhere to the following rules:
- For each team, multiple account registrations are strictly prohibited.
- There is a 72-hour waiting period between each submission.
- Each team may submit up to 3 total submission during the span of the competition.
Participants
If you are interested in joining the challenge, please register here:
RegisterLoginTo see the entire menu bar on top of this site, with registration and login information, please use a large enough browser.